Machine-vision lip reading: algorithm design and system development
SRTP: fully automated incremental AICLD corpus (~1.4M samples / 5k+ speakers), lip-reading models and training, outputs include IEEE TIP and other Q1 papers, plus invention patents and software copyrights.
Fuzhou University College of Electrical Engineering and Automation
May 2024——present
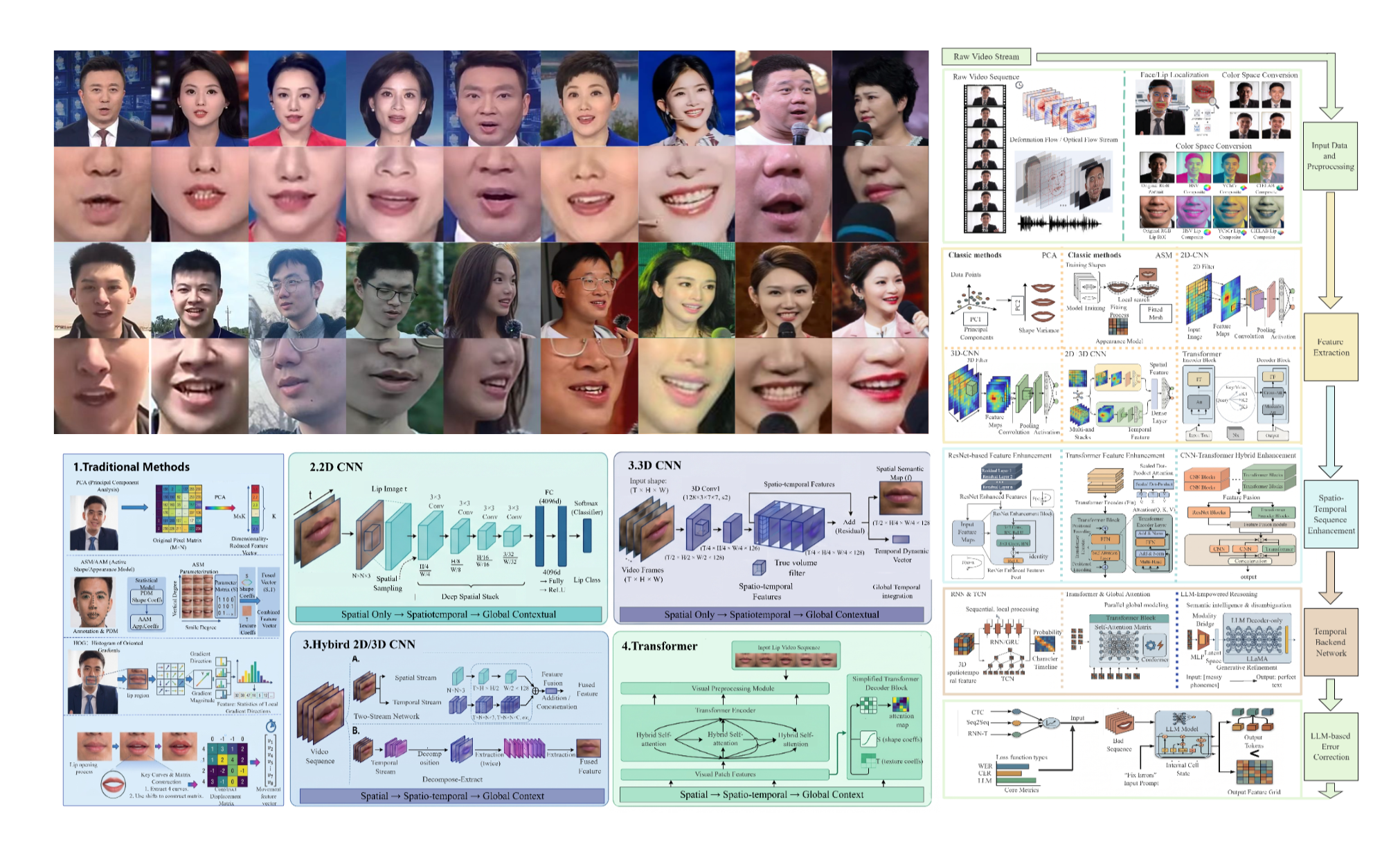
Background
As AI, computer vision, and NLP converge, lip reading offers audio-free communication with broad impact, yet Mandarin lip reading faces a dual bottleneck: data infrastructure (limited corpus scale, heavy manual labeling) and model design (weak low-resource generalization, insufficient temporal modeling), with few systematic surveys of how the field evolved. This SRTP (College Student Innovation Training Program) focuses on corpus automation and algorithmic renewal—building an incrementally scalable Mandarin lip-reading dataset, modernizing low-resource architectures, and clarifying technical lineages to fill gaps and provide practical support.
- For high labeling cost, poor A/V sync, and slow scaling in Mandarin lip-reading corpora, built a distributed AI-assisted incremental pipeline—FFmpeg preprocessing, shot-boundary and SyncNet alignment, Aeneas/MFA hierarchical forced alignment, and MTCNN+KCF ROI extraction with ResNet-18 speaker clustering—yielding AICLD at 1,400,000+ samples, 5,238 speakers, 110+ hours, and 3,000+ daily adds, backing the IEEE TIP dataset paper and invention patents.
- Video-only releases struggled with layered experiments and drifting public statistics. Defined a unified metadata schema (pose, key frames, reliability) with sampling QA; built a multi-dimensional AICLD matrix over scale, preprocessing, temporal resolution, and key-frame sampling, using ablations to set an optimal processing paradigm for verifiable public metrics.
- Led AICLD platform architecture and full-stack development: a Streamlit portal for indexing, versioning, and tasks, plus cloud incremental ingest, annotation/QA workflows, real-time monitoring, and technical/data-request documentation for daily updates and compliant team access (software copyright).
- For low-resource overfitting and large train–validation gaps, built a PyTorch stack with SimMIM pre-training, Swin V2, GN temporal branches, and staged curricula; on AICLD-500, Top-1 improved by 1.91 points over SwinLip with a much narrower generalization gap, supporting the TASLP paper.
- For scattered VSR literature lacking an end-to-end preprocessing-to-decoding view, helped organize five technological eras and typical architectures, established a dataset taxonomy over granularity, environment, language, and modality, and drafted open-problem and future-direction sections forming a citable reference framework for the ARC survey.
Research outputs
-
Structured Temporal Regularization and Curriculum Optimization for Visual Speech Recognition
2026 · Under Review · IEEE Transactions on Audio, Speech, and Language Processing (JCR Q1, IF 5.2) · Under Review
-
AICLD : AI-assisted Incremental Chinese Lip-reading Database
2026 · Under Review · IEEE Transactions on Image Processing (JCR Q1, IF 15.3) · Under Review
-
The Evolution of Visual Speech Recognition: From Deep Spatio-Temporal Modeling to LLM-Guided Reasoning
2026 · Under Review · International Journal of Computer Vision (JCR Q1, IF 10.3) · Under Review
-
一种AI 辅助的大规模唇语识别数据集自动化构建方法 AI-Assisted Automated Construction Method for Large-Scale Lip-Reading Datasets
2026 · Chinese invention patent · Substantive Examination
-
AICLD 人工智能辅助增量式中文唇语识别数据库平台 AICLD Platform for AI-Assisted Incremental Chinese Lip-Reading Database
2026 · Computer software copyright registration · Registered
Stack
Python, PyTorch, Swin Transformer, FFmpeg tooling