【深度学习实战】阿里“小云”语音唤醒模型部署全攻略:从环境填坑到执行推理
文章讲解如何在 Linux 上部署阿里 iic 的 speech_charctc_kws_phone-xiaoyun 唤醒模型:锁定 modelscope、datasets、funasr 版本避免冲突,用 snapshot_download 拉取权重,并通过 Monkey Patch 修复 FunASR 1.3.1 的 writer 属性 Bug。同时强调 16kHz 单声道 WAV 输入要求及 FFmpeg 转码方法,给出完整 test_kws.py 推理示例。
1. 背景介绍
语音唤醒(Keyword Spotting, KWS)是智能家居、手机助手的核心功能。本文将带大家部署阿里 iic 实验室开源的 speech_charctc_kws_phone-xiaoyun 模型。该模型基于 FSMN-CTC 架构,专门针对移动端优化,具有极高的推理效率。
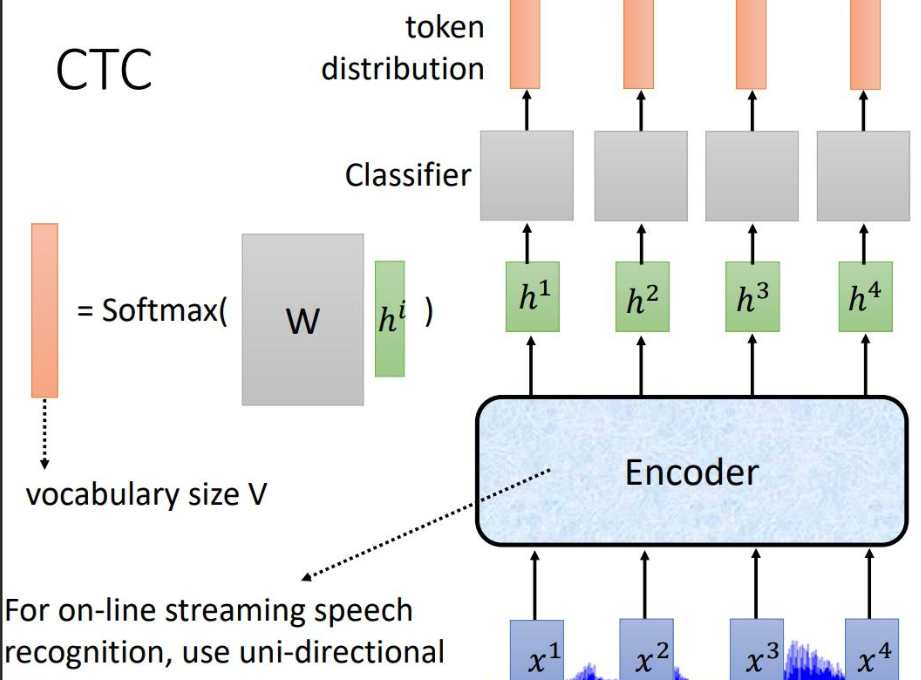
我们将解决部署过程中常见的库版本冲突、缺失依赖包以及官方库内部 Bug 等硬核问题。
2. 实验环境准备
- 硬件:NVIDIA GeForce RTX 4090 D (24GB 显存)
- 操作系统:Linux
- Python 环境:Python 3.11 + PyTorch 2.6.0
- 核心框架:ModelScope (模型下载) + FunASR (推理框架)
3. 环境配置与“填坑”指南
部署的第一步是安装依赖库。由于 Hugging Face 的 datasets 库频繁更新,会导致 ModelScope 报错,我们需要锁定特定版本。
3.1 安装核心库
执行以下命令,建议锁定 datasets 版本以避开 ImportError:
# 卸载可能冲突的旧版本
pip uninstall -y modelscope datasets
# 安装经过验证的稳定组合
pip install modelscope==1.13.3 datasets==2.16.0 funasr==1.3.1 torchaudio
3.2 解决音频后端问题
如果系统没有安装 ffmpeg,torchaudio 会自动接管,但为了保证音频加载不出错,可以额外安装:
pip install soundfile librosa
4. 模型下载
并不是所有的服务器都预装了模型。我们使用 ModelScope 的 SDK 编写一个脚本,将模型下载到本地。
下载逻辑说明:
ModelScope 会将模型下载到 ~/.cache/modelscope/hub/ 目录下。
from modelscope.hub.snapshot_download import snapshot_download
# 指定模型 ID 和版本号
model_id = 'iic/speech_charctc_kws_phone-xiaoyun'
model_dir = snapshot_download(model_id, revision='v1.1.3')
print(f"模型已成功下载至:{model_dir}")
5. 核心代码实现(包含 Bug 修复补丁)
在实际推理中,FunASR 1.3.1 版本在处理 KWS 任务时存在一个内部 Bug(缺少 writer 属性)。我们通过 Monkey Patch(猴子补丁) 动态修复它。
5.1 完整推理脚本 test_kws.py
import os
import sys
import torch
from funasr import AutoModel
from modelscope.hub.snapshot_download import snapshot_download
# 1. 下载并获取模型路径
model_id = 'iic/speech_charctc_kws_phone-xiaoyun'
model_path = snapshot_download(model_id, revision='v1.1.3')
print(f"正在加载模型自:{model_path}")
# 2. 初始化 FunASR 模型
# 必须显式指定 keywords 参数(通常为 '小云小云')
model = AutoModel(model=model_path, keywords="小云小云")
# 3. 【核心补丁】修复 'FsmnKWS' object has no attribute 'writer' 报错
# 这是 FunASR 1.3.1 的一个官方 Bug,手动为其添加日志占位符
if not hasattr(model.model, 'writer'):
model.model.writer = {"detect": {}}
print("已成功应用推理补丁!")
print("--- 模型加载成功 ---")
# 4. 推理测试
audio_path = "test.wav" # 请确保当前目录下有这个 16k 采样率的文件
if os.path.exists(audio_path):
print(f"开始分析音频:{audio_path}")
# generate 推理接口
res = model.generate(input=audio_path, is_final=True)
print("\n" + "="*40)
print(f"最终识别结果: {res}")
print("="*40)
else:
print(f"\n[环境就绪] 请上传 16000Hz 采样率的 {audio_path} 进行测试。")
6. 测试与音频准备
唤醒模型对音频格式有极高的硬性要求,不满足以下条件的音频将无法被识别(结果返回 rejected):
- 采样率:16000 Hz (16k)
- 声道:单声道 (Mono)
- 格式:16bit PCM WAV
6.1 使用 FFmpeg 转换音频
如果你从手机录制的音频(通常是 48k)需要转换:
ffmpeg -i my_voice.wav -ar 16000 -ac 1 -f wav test.wav
6.2 结果分析
运行 python test_kws.py 后,你会看到:
-
[{'key': 'test', 'text': 'rejected'}]:说明模型正常工作,但音频中未检测到“小云小云”,或采样率不对。 -
[{'key': 'test', 'text': '小云小云', 'score': 0.98}]:恭喜你,唤醒成功!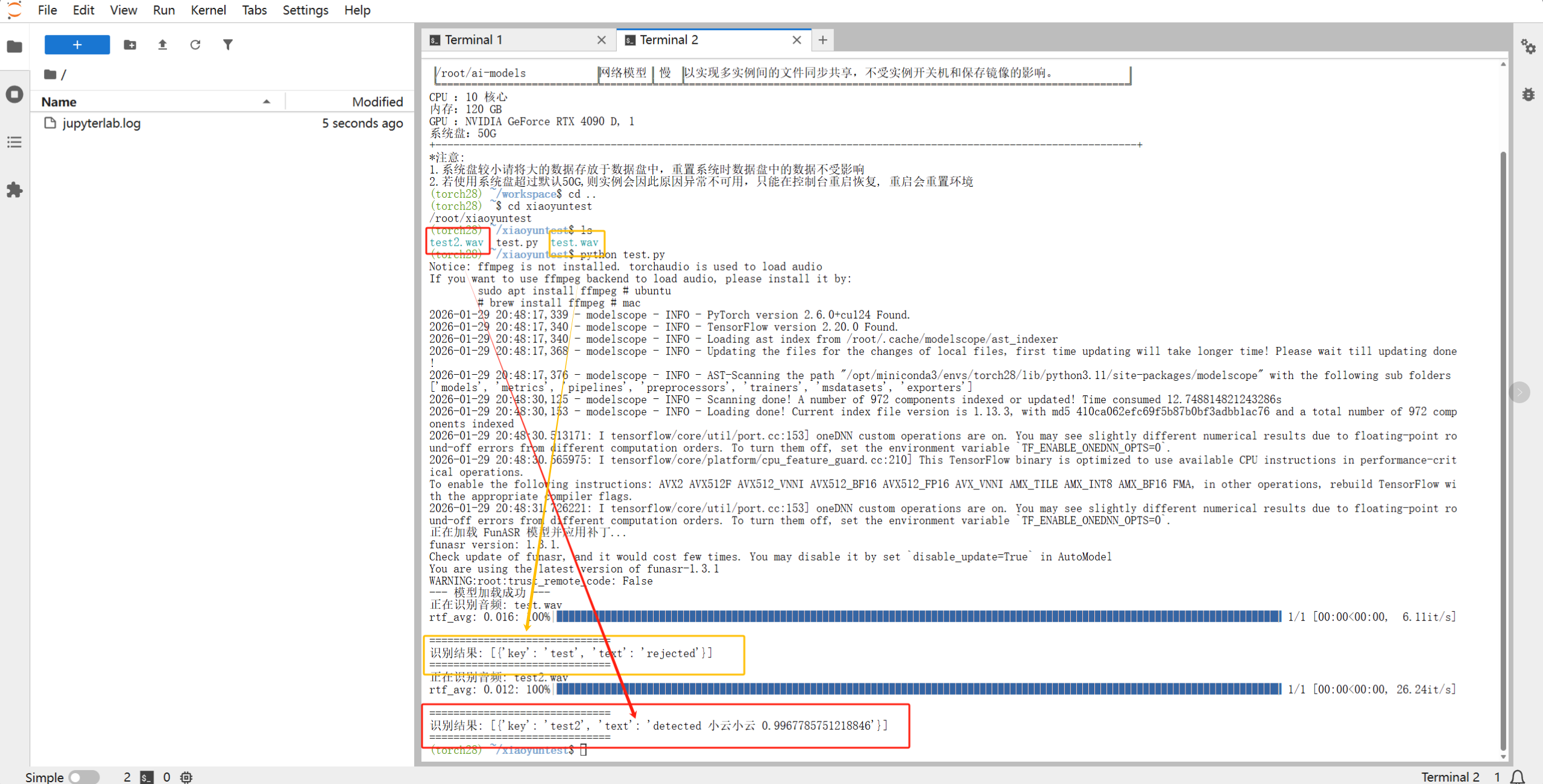
7. 避坑总结
- 路径坑:ModelScope 的
pipeline模式经常找不到kws_util脚本,切换到FunASR框架可以完美避开路径依赖。 - 版本坑:
datasets库一定要降级到2.16.0左右,否则 ModelScope 初始化就会崩溃。 - 补丁坑:报错
AttributeError: ... object has no attribute 'writer'时,不要去改库源码,直接在脚本里用hasattr动态添加属性即可。
8. 结语
阿里小云语音唤醒模型体积小、响应快,非常适合作为 AI 项目的语音入口。通过本文的“保姆级”教学,相信你已经能够在任何 Linux 服务器上流畅运行它。
如果你在部署中遇到其他报错,欢迎在评论区留言讨论!
作者:ChenAI_TGF
发布于:2026年1月
【深度學習實戰】阿里“小云”語音喚醒模型部署全攻略:從環境填坑到執行推理
文章講解如何在 Linux 上部署阿里 iic 的 speech_charctc_kws_phone-xiaoyun 喚醒模型:鎖定 modelscope、datasets、funasr 版本避免衝突,用 snapshot_download 拉取權重,並通過 Monkey Patch 修復 FunASR 1.3.1 的 writer 屬性 Bug。同時強調 16kHz 單聲道 WAV 輸入要求及 FFmpeg 轉碼方法,給出完整 test_kws.py 推理示例。
來源:https://blog.csdn.net/2403_87969572/article/details/157516729
抓取時間(ISO本地):2026-05-18 05:17:31
1. 背景介紹
語音喚醒(Keyword Spotting, KWS)是智慧家居、手機助手的核心功能。本文將帶大家部署阿里 iic 實驗室開源的 speech_charctc_kws_phone-xiaoyun 模型。該模型基於 FSMN-CTC 架構,專門針對移動端最佳化,具有極高的推理效率。
我們將解決部署過程中常見的庫版本衝突、缺失依賴包以及官方庫內部 Bug 等硬核問題。
2. 實驗環境準備
- 硬體:NVIDIA GeForce RTX 4090 D (24GB 視訊記憶體)
- 作業系統:Linux
- Python 環境:Python 3.11 + PyTorch 2.6.0
- 核心框架:ModelScope (模型下載) + FunASR (推理框架)
3. 環境配置與“填坑”指南
部署的第一步是安裝依賴庫。由於 Hugging Face 的 datasets 庫頻繁更新,會導致 ModelScope 報錯,我們需要鎖定特定版本。
3.1 安裝核心庫
執行以下命令,建議鎖定 datasets 版本以避開 ImportError:
# 解除安裝可能衝突的舊版本
pip uninstall -y modelscope datasets
# 安裝經過驗證的穩定組合
pip install modelscope==1.13.3 datasets==2.16.0 funasr==1.3.1 torchaudio
3.2 解決音訊後端問題
如果系統沒有安裝 ffmpeg,torchaudio 會自動接管,但為了保證音訊載入不出錯,可以額外安裝:
pip install soundfile librosa
4. 模型下載
並不是所有的伺服器都預裝了模型。我們使用 ModelScope 的 SDK 編寫一個指令碼,將模型下載到本地。
下載邏輯說明:
ModelScope 會將模型下載到 ~/.cache/modelscope/hub/ 目錄下。
from modelscope.hub.snapshot_download import snapshot_download
# 指定模型 ID 和版本號
model_id = 'iic/speech_charctc_kws_phone-xiaoyun'
model_dir = snapshot_download(model_id, revision='v1.1.3')
print(f"模型已成功下載至:{model_dir}")
5. 核心程式碼實現(包含 Bug 修復補丁)
在實際推理中,FunASR 1.3.1 版本在處理 KWS 任務時存在一個內部 Bug(缺少 writer 屬性)。我們透過 Monkey Patch(猴子補丁) 動態修復它。
5.1 完整推理指令碼 test_kws.py
import os
import sys
import torch
from funasr import AutoModel
from modelscope.hub.snapshot_download import snapshot_download
# 1. 下載並獲取模型路徑
model_id = 'iic/speech_charctc_kws_phone-xiaoyun'
model_path = snapshot_download(model_id, revision='v1.1.3')
print(f"正在載入模型自:{model_path}")
# 2. 初始化 FunASR 模型
# 必須顯式指定 keywords 引數(通常為 '小云小云')
model = AutoModel(model=model_path, keywords="小云小云")
# 3. 【核心補丁】修復 'FsmnKWS' object has no attribute 'writer' 報錯
# 這是 FunASR 1.3.1 的一個官方 Bug,手動為其新增日誌佔位符
if not hasattr(model.model, 'writer'):
model.model.writer = {"detect": {}}
print("已成功應用推理補丁!")
print("--- 模型載入成功 ---")
# 4. 推理測試
audio_path = "test.wav" # 請確保當前目錄下有這個 16k 取樣率的檔案
if os.path.exists(audio_path):
print(f"開始分析音訊:{audio_path}")
# generate 推理介面
res = model.generate(input=audio_path, is_final=True)
print("\n" + "="*40)
print(f"最終識別結果: {res}")
print("="*40)
else:
print(f"\n[環境就緒] 請上傳 16000Hz 取樣率的 {audio_path} 進行測試。")
6. 測試與音訊準備
喚醒模型對音訊格式有極高的硬性要求,不滿足以下條件的音訊將無法被識別(結果返回 rejected):
- 取樣率:16000 Hz (16k)
- 聲道:單聲道 (Mono)
- 格式:16bit PCM WAV
6.1 使用 FFmpeg 轉換音訊
如果你從手機錄製的音訊(通常是 48k)需要轉換:
ffmpeg -i my_voice.wav -ar 16000 -ac 1 -f wav test.wav
6.2 結果分析
執行 python test_kws.py 後,你會看到:
-
[{'key': 'test', 'text': 'rejected'}]:說明模型正常工作,但音訊中未檢測到“小云小云”,或取樣率不對。 -
[{'key': 'test', 'text': '小云小云', 'score': 0.98}]:恭喜你,喚醒成功!
7. 避坑總結
- 路徑坑:ModelScope 的
pipeline模式經常找不到kws_util指令碼,切換到FunASR框架可以完美避開路徑依賴。 - 版本坑:
datasets庫一定要降級到2.16.0左右,否則 ModelScope 初始化就會崩潰。 - 補丁坑:報錯
AttributeError: ... object has no attribute 'writer'時,不要去改庫原始碼,直接在指令碼里用hasattr動態新增屬性即可。
8. 結語
阿里小云語音喚醒模型體積小、響應快,非常適合作為 AI 專案的語音入口。透過本文的“保姆級”教學,相信你已經能夠在任何 Linux 伺服器上流暢執行它。
如果你在部署中遇到其他報錯,歡迎在評論區留言討論!
作者:ChenAI_TGF
釋出於:2026年1月
[Deep Learning] Alibaba “Xiaoyun” Wake-Word Model: Full Deployment from Environment Fixes to Inference
GPU: NVIDIA GeForce RTX 4090 D (24GB) Python: 3.11 + PyTorch 2.6.0
Captured at (local ISO): 2026-05-18 05:17:31
1. Background
Keyword spotting (KWS) powers smart home and phone assistants. This post deploys Alibaba iic’s open speech_charctc_kws_phone-xiaoyun model—FSMN-CTC architecture tuned for mobile, with high inference efficiency.
We address library version conflicts, missing dependencies, and upstream bugs you will hit in practice.
2. Environment
- GPU: NVIDIA GeForce RTX 4090 D (24GB)
- OS: Linux
- Python: 3.11 + PyTorch 2.6.0
- Stack: ModelScope (download) + FunASR (inference)
3. Setup and troubleshooting
Install dependencies first. Lock datasets because Hugging Face updates break ModelScope.
3.1 Core packages
pip uninstall -y modelscope datasets
pip install modelscope==1.13.3 datasets==2.16.0 funasr==1.3.1 torchaudio
3.2 Audio backend
pip install soundfile librosa
4. Model download
Use ModelScope SDK; cache path is typically ~/.cache/modelscope/hub/.
from modelscope.hub.snapshot_download import snapshot_download
model_id = 'iic/speech_charctc_kws_phone-xiaoyun'
model_dir = snapshot_download(model_id, revision='v1.1.3')
print(f"Model downloaded to: {model_dir}")
5. Inference code (with bug patch)
FunASR 1.3.1 KWS path can miss a writer attribute. Fix with a monkey patch.
5.1 Full script test_kws.py
import os
import sys
import torch
from funasr import AutoModel
from modelscope.hub.snapshot_download import snapshot_download
# 1. Download model
model_id = 'iic/speech_charctc_kws_phone-xiaoyun'
model_path = snapshot_download(model_id, revision='v1.1.3')
print(f"Loading from: {model_path}")
# 2. Init FunASR (keywords required)
model = AutoModel(model=model_path, keywords="小云小云")
# 3. Patch missing 'writer' on FsmnKWS (FunASR 1.3.1 bug)
if not hasattr(model.model, 'writer'):
model.model.writer = {"detect": {}}
print("Patch applied.")
print("--- Model loaded ---")
# 4. Inference
audio_path = "test.wav" # 16 kHz mono WAV in cwd
if os.path.exists(audio_path):
print(f"Analyzing: {audio_path}")
res = model.generate(input=audio_path, is_final=True)
print("\n" + "="*40)
print(f"Result: {res}")
print("="*40)
else:
print(f"\n[Ready] Upload 16000Hz {audio_path} to test.")
6. Testing and audio format
Wake-word models are strict; wrong format returns rejected:
- Sample rate: 16000 Hz
- Channels: mono
- Format: 16-bit PCM WAV
6.1 FFmpeg conversion
ffmpeg -i my_voice.wav -ar 16000 -ac 1 -f wav test.wav
6.2 Interpreting output
After python test_kws.py:
-
[{'key': 'test', 'text': 'rejected'}]: model OK, no wake phrase or bad audio. -
[{'key': 'test', 'text': '小云小云', 'score': 0.98}]: wake success.
7. Pitfall summary
- Paths: ModelScope
pipelinemay misskws_util; FunASR avoids that. - Versions: pin
datasets~2.16.0 or ModelScope init fails. - Patch: for
AttributeError: ... 'writer', usehasattrpatch instead of editing site-packages.
8. Closing
The Xiaoyun KWS model is small and fast—a good voice entry for AI projects. With this guide you should run it smoothly on Linux servers.
Comment if you hit other errors.
Author: ChenAI_TGF
Published: January 2026